Below you will find a list of the stalls at the CLARIN Bazaar. The CLARIN Bazaar is an informal space at the CLARIN Annual Conference where you can meet people from other centres and countries, find out about their work in progress, exchange ideas, and talk to people about future collaborations. This year, the Bazaar will return to its in-person, highly interactive format.
Bazaar Presentations (sorted by topical category)
CLARIN Core
Presentation of a near-final draft of the CLARIN Resource Guides for Online and Desktop Tools for Querying a Language Corpus, asking participants for updates, suggestions of missing items, and identifying further gaps in the coverage of this field.
The CMDI task force has been continuing the work on the design and implementation of a set of ‘core metadata components’, with the aim of simplifying the creation of metadata for a wide variety of use cases that is both FAIR and optimised for the CLARIN infrastructure. Now in a more advanced development stage, we still welcome ideas and feedback from metadata creators and modellers, repository managers, developers of software processing metadata, and anyone else with experience with or interest in metadata in the context of CLARIN and the broader research infrastructure landscape. Of course, we are also there to answer your CMDI-related questions, or discuss any other matters related to metadata in CLARIN.
The new linkchecker-web REST API provides a mean for registered users to upload links to CLARIN's link checker and to receive status results for these links. In this stall I'm going to explain briefly the workflow for registering, uploading links and receiving results. Further on I will demonstrate how to upload a JSON list of URLs to check and receive the results with curl.
CLARIN-DSpace is a digital repository meeting the CLARIN B centre requirements for many years. Implementing many new features into the repository required substantial effort, but proved itself and has become popular among CLARIN B-centres. With the surprise announcement of DSpace 5 ending support by the end of 2022, the support of CLARIN-DSpace could quickly become resource intensive.
TEITOK is an online corpus infrastructure, maintained at LINDAT in Prague. Corpus files are stored in TEI/XML, and an NLP pipeline can be run automatically on the server, by default using UDPIPE. The annotated TEI/XML files are then compiled into a searchable corpus. The system is explicitly designed to allow linguists or DH researchers to maintain their own corpora, where they can correct transcription mistake, normalise the spelling in a non-destructive manner, correct NLP errors, add additional manual annotations, etc. The system can display many types of corpora, including aligned multimedia corpora with facsimile images, audio, or video. The standard searchable corpus uses the Corpus WorkBench, but the corpus can also be exported to a number of different corpus management systems, and queried either directly in TEITOK, as is done at LINDAT using PML-TQ, or made available in another online corpus tool, as is done at LINDAT with Kontext. Corpora can be hosted by LINDAT, or in a local TEITOK installation. We will demonstrate various use cases of TEITOK corpora, both at LINDAT and at various universities around the world.
In Norway the National Library, together with the University libraries of Tromsø and Bergen, are partner institutions in the national CLARIN node CLARINO. Our libraries work within CLARINO, currently in the construction phase of the upgrade project CLARINO+, with the other partners to safeguard persistence and longevity of language resources and services. Long-term storage, long-term accessibility, metadata management and user support and outreach are among the tasks where library services play an important part. The running of repositories is one important type of service, other services include creation of resources into CLARIN based on library collections, tools and activities related to Digital Humanities, and the provision of guidelines and recommendations on data and metadata curation. Our poster will give an overview of the roles of our libraries in CLARINO, and thus follow up on the workshop 'CLARIN and Libraries' which was held in The Hague on 9 and 10 May this year. We hope that our poster will provide an opportunity for discussions of types of co-operation, roles within CLARIN, and not least the common challenges that the long-term running and upgrade of the infrastructures pose.
CLARIN National Nodes Highlights
LiRI is a technology platform to serve the needs of quantitative linguistic research at UZH, Switzerland and beyond. LiRI provides technical and practical support for research projects in the field of linguistics, language sciences and language-related disciplines at the University of Zurich and beyond. LiRI services fall into three main categories:
- Data acquisition: The LiRI lab has equipment and software for generating and collecting linguistic research data. The facilities can be used by scientists or other users interested in natural language data (i.e. audiovisual, textual and speech data), and by language researchers working on experimental data (e.g. eye-tracking, electroencephalographic, behavioural).
- Data management: LiRI can set up and manage customised virtual machine (VM) servers for the purposes of processing, analysis, storage and backup of linguistic research data. These VM servers are part of the ScienceCloud environment of the University of Zurich and are accessible both within the UZH network and world wide. Additional software can be installed for specific research requirements. Server access can be customised so that, for example, data is available to a particular research group or specific users only. These data management services are not limited to researchers using the LiRI facilities to collect their data. Language scientists who wish to analyse and temporarily store their self-collected data can also use the LiRI server infrastructure.
- Collaboration and support: The Linguistic Research Infrastructure offers technical and methodological assistance to researchers on how best to collect, process and analyse the linguistic data they require. A project's infrastructure needs can be discussed in an initial, free of charge consultation. Depending on the complexity of the project, support could range from occasional guidance to LiRI managing all data acquisition and processing. LiRI staff members can also advise on project budgets and data management plans.
CLARIN-PL has been developed since 2008 by six research units as a language technology infrastructure for Polish science, with a particular focus on Social Sciences and Humanities. Our primary goal is to develop a system of basic language tools and resources primarily for Polish, but also for Slavic languages in general. In addition, semi-automatically, but also to large extent manually built mappings between Polish and English resources (especially lexical) offer an interface to English resources and have been utilised in many tools and research applications. During years of infrastructure development, we have been able to create dozens of tools and resources, including parsing, tagging, lemmatisation, Named Entity Recognition and Disambiguation, Entity Linking, speech recognition, Information Extraction, and Retrieval. Our high-quality resources, e.g. plWordNet manually linked to Princeton WordNet, VeSNet - Linked Open Data for Polish with the links to word resources (thesauri and ontologies), manually annotated corpus for Polish - KPWr, are recognised among Polish researchers.
In our close cooperation with users, we have discovered that many of our open tools and resources have commercial applications in addition to their primary research use. Therefore, in 2020, we established the CLARIN-PL-Biz consortium, which also includes 30 companies representing the commercial sector. Some 60% of our products and services are to remain open, also for research use, while 40% are to be constructed in cooperation with the commercial sector, especially taking from them advice on their needs. The post-project CLARIN-PL-Biz R&D infrastructure should be self-financed to some extent due to funds acquired from the market. Our research agenda, approved by the Polish Ministry of Education and Science, includes several types of services to be offered after 2023 by CLARIN-PL-Biz R&D infrastructure: collection and permanent storage of linguistic data, services for extracting information and knowledge from big linguistic data, semantic indexing and searching of collected data, and IT environment for creating dialogue systems.
Here, we present selected results of our work in advanced progress and our plans for the future shape of the infrastructure that has significantly evolved in comparison to the project proposal, especially due to the very valuable experience gained from the cooperation with the commercial sector.
In this stall, we showcase Switzerland: The creation of the CLARIN-CH consortium, the infrastructure and the national assets in terms of language resources, tools and expertise, as well as the efforts made to place access to research infrastructures in the SSH field at the forefront of Swiss research politics. The CLARIN-CH consortium was formally founded in December 2020 by several higher education institutions and continues to welcome new members. The declared objectives of the CLARIN-CH consortium are to: (i) foster the sharing of resources and expertise at the national and the European levels, (ii) encourage collaborations by implementing focused collaborative and cross-institutional working groups, and (iii) build up a complete CLARIN-CH infrastructure ready to be connected to the European CLARIN infrastructure.
The CLARIN-CH scientific community is a cross-institutional national network of scholars presenting a large array of language-related areas of expertise. Switzerland presents a high number of resources (monolingual and multilingual corpora, databases, dictionaries, didactic resources, software, etc.) which will be, step by step, rendered interoperable at the national and European levels. CLARIN-CH has developed a strong cooperation with the national Linguistic Research Infrastructure, which will be the Swiss B-centre, and SWISSUbase, which is the national data publication and archiving platform. In addition, starting from the national working groups, we plan to create one or more K-centres. The CLARIN-CH consortium is also very active at the level of the Swiss research politics, namely in the 'SSH Research Infrastructures in Switzerland' initiative and in the newly created Swiss EOSC group. To conclude, thanks to the efforts made by the consortium in the last two years, Switzerland is now ready to request its observer status to CLARIN ERIC.
Training and Knowledge Exchange
The aim of the CLARIN Ambassadors programme is to raise awareness about and encourage participation in CLARIN ERIC in disciplines and communities that are not yet fully integrated in CLARIN.
Current CLARIN ambassadors are Paul Rayson (Professor in Computer Science at Lancaster University, UK), Satu Saalasti (University lecturer of Speech and Language Pathology at the University of Helsinki, Finland), Eva Soroli (Associate Professor of Psycholinguistics at the University of Lille, France).
Paul, Satu and Eva have been appointed from September 2021 until September 2023. Since last year they have been active in their respective communities, disseminating CLARIN resources and services in conferences and workshops both online and onsite, and promoting CLARIN in their networks and projects. In the Ambassadors’ Stall you will be able to meet them and learn more about how they help to spread the CLARIN word in the fields of Corpus Linguistics and Computer Science, Speech and Language Pathology, Language Acquisition and Psycholinguistics.
{kind=link}
Are you a student or a graduate seeking to improve your skills in Digital Humanities (DH) abroad?
Are you a lecturer teaching a course in DH or a related field, seeking to increase the visibility of your course outside your university network?
Are you a researcher interested in using the DH course registry for research purposes?
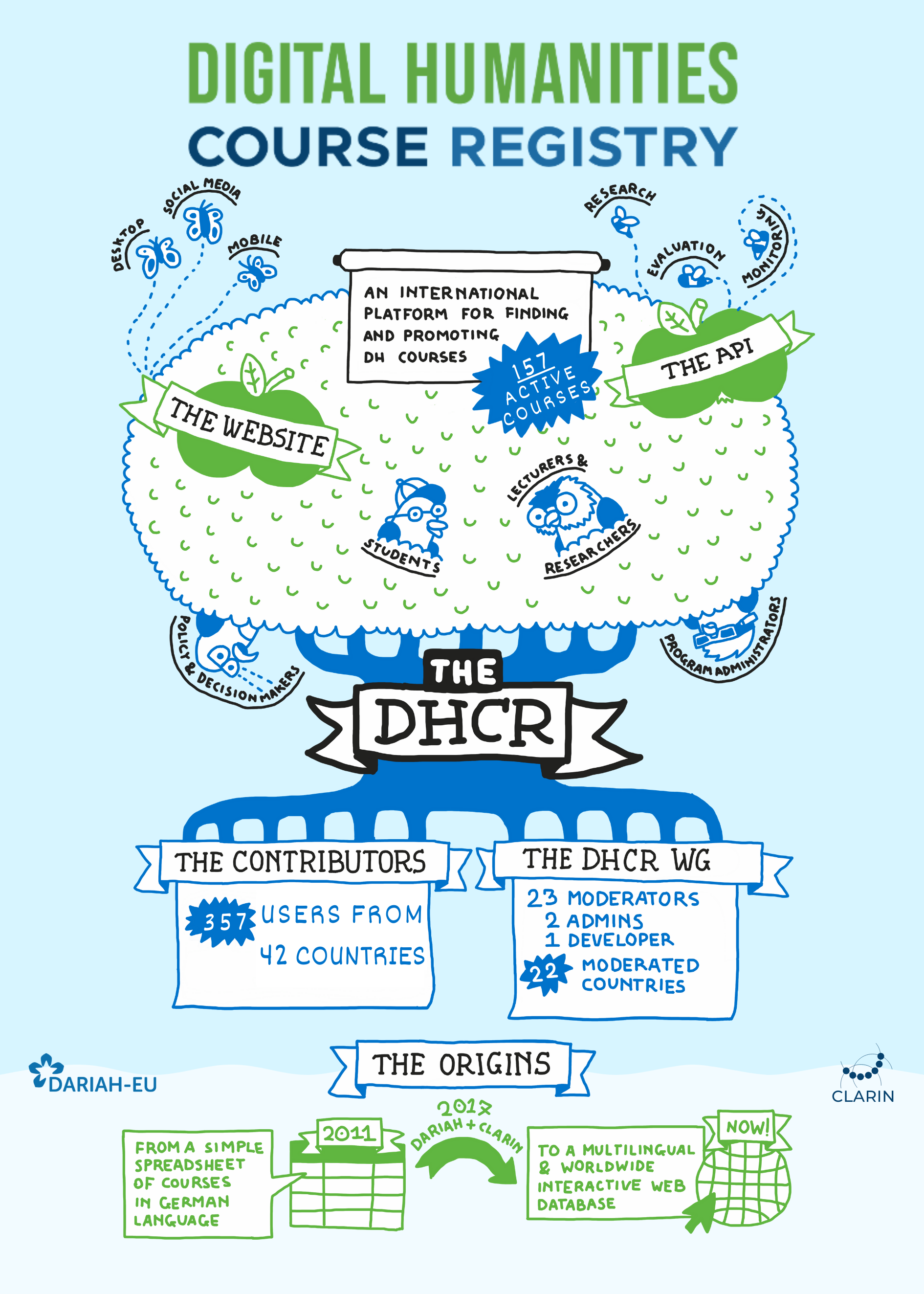
Then come to our stand at the CLARIN Bazaar and get to know the DH Course Registry, a joint effort by CLARIN ERIC and DARIAH-EU, designed to showcase DH courses and training programmes across Europe and beyond.
Increasing the visibility of DH training activities – both on the local and the European level – has been of great concern to the DH community, not only to attract more students but also as a way of consolidating DH as an academic discipline.
As traditional academic structures are rather resistant to the inherent interdisciplinary nature of DH initiatives, we need to look to other dissemination channels and go beyond barriers to reach out to the public outside of an individual university. The DH Course Registry was built for just this purpose.
In addition, we offer an API to export the course data from the DHCR database for further analysis, such as diachronic research or custom web and/or data visualisation. As an example, please take a look at the winning projects of the ACDH-CH virtual Hackathon, funded by CLARIAH-AT with the data of the DH Course Registry.
We are happy to demonstrate the DH Course Registry application, tell you more about it and answer your questions at the CLARIN Bazaar. DH Course Registry promo video.
The goal of the UPSKILLS project is to identify and tackle the gaps in digital skills through the development of a new curriculum component and supporting the embedding of adequate materials in existing programmes to prepare linguistics and language students for today’s jobs in the language industry. In this stall, we will present work in progress, focusing on one of CLARIN's tasks in the project: integrating research infrastructures into teaching. We will demonstrate a modular course, entitled Introduction to Language Data: Standards and Repositories, and ask for feedback from the teachers present at the conference.
We have designed notebooks to help getting started with the processing of historical text resources (from Europeana Newspapers) with natural language processing (NLP) tools (from CLARIN) using Jupyter notebooks. We are happy to demonstrate, explain and discuss these notebooks, and the use of computational notebooks for educational and demonstration purposes more broadly! See https://www.clarin.eu/notebooks and https://github.com/clarin-eric/europeana-newspapers-notebooks
Data Curation Using NLP
In addition to the well-established benefits to language technology, syntactically annotated corpora, i.e. treebanks, represent an equally invaluable methodological tool for research in linguistics and other language-based disciplines. Nevertheless, this methodological potential is yet to be fully exploited, which can partially be explained by the fact that investigating this complex type of data presents a challenge for researchers with little technical background. In this presentation, I will present some recently developed tools and services supported by CLARIN.SI that aim to overcome this infrastructural gap in Slovene linguistics. Specifically, I will present the Drevesnik online service for querying parsed corpora, the STARK command-line tool for bottom-up tree extraction, and an online graphical user interface for the CLASSLA-Stanza NLP pipeline. All these products incorporate dependency treebanks annotated using the Universal Dependencies annotation scheme and can thus be considered relatively language-independent.
The topic modelling tool Topics2Themes is currently being evaluated and further developed at Språkbanken Sam, which is a part of SWE-CLARIN, as well as at the Centre for Digital Humanities Uppsala. It has previously been developed at the Information and Software Visualisation group at Linnaeus University, as well as at the Applied CompLing Discourse Research Lab at the University of Potsdam.
The tool has previously been applied to a wide range of text collections, including online discussions on vaccinations, micro blogs in Japanese and folk legends. We have recently applied the tool to different types of texts related to climate change. The texts include tweets in German, journal editorials in English, as well as Swedish government official reports.
Topics2Themes provides a graphical user interface which can be used for exploring the output of the topic modelling algorithm applied to the text collection. The interface consists of four panels. One panel contains elements representing the automatically extracted topics, another panel contains the terms associated with the topics extracted, and a third panel contains the texts associated with the topics. The purpose of the tool is not only to automatically extract reoccurring topics, but to also support the user in manually analysing the texts associated with the topics. The tool therefore contains a fourth panel, to which the user can add reoccurring themes identified when analysing the automatically extracted texts.
We present a cooperation project between the National Library of Norway and The Language Council of Norway, where we crawl and classify publicly available documents from the websites of Norwegian state institutions. According to The Norwegian Language Act ('Språklova'), the two official written languages of Norwegian (Bokmål and Nynorsk) have to be represented by at least 25% each in publicly available documents from state institutions. Earlier, numbers were reported manually by each institution. In the current project, the process was largely automatised using NLP. At the same time, we create a corpus that can be used for other purposes.
We do a yearly deep crawl of public content from Norwegian public entities and download around 2 million (unique) web pages. Then, we extract natural language from the downloaded documents using various text extraction methods (e.g. boilerplate removal, OCR) and finally classify the documents. The resulting corpus for the last year consists of approximately 4.1 billion tokens in total, which makes it one of the largest freely available resources for Norwegian Bokmål and Nynorsk. In addition to Norwegian, the corpus contains texts in Northern Sami, Lule Sami, Southern Sami, English and various other languages. The data are made available for download in the repository of the Norwegian Language Bank under the Norwegian License for Open Government Data (NLOD).
In this stall, we present the pipeline itself, challenges and opportunities in the data.
Terminology, i.e., the specialised vocabulary of a domain, is an integral part of all specialised communication, since terms can be used to concisely express very specific concepts. Using the correct terminology is crucial but can be difficult for non-domain specialists. Translators and interpreters specifically, know the importance of terminology management. Automatic term extraction is a technology that allows users to automatically identify terms in text, to facilitate this part of the term management process. Multilingual automatic term extraction can be used to identify pairs of potentially equivalent terms cross-lingually.
D-Terminer is an online demo for automatic terminology extraction. It is based on research that investigates supervised machine learning approaches to this task and is trained on the ACTER dataset (Annotated Corpora for Term Extraction Research). You can use D-Terminer for monolingual term extraction (upload one or more .txt files, see all candidate terms in that text), and bilingual term extraction from parallel corpora (upload one or more translation memories (.tmx files) and see all candidate terms in the source language, with potential equivalents in the target language). The demo is freely available at https://lt3.ugent.be/dterminer/ and will be further improved based on new research and user feedback.
The Text Tonsorium (TT) is an open source web application for Natural Language Processing (NLP) that is publicly available at https://clarin.dk/clarindk/tools-texton.jsp, and that can even be installed on your laptop.
The TT is to NLP as a salon de beauté (= tonsorium) is to installing artificial hair integrations: Users provide input and state their wishes, but do not need to know how to generate the desired result. This TT automatically assembles NLP tools into a viable workflow design and then enacts it with the user's input. The absence of human workflow architects makes the TT flexible and reliable.
Even though Text Tonsorium’s user interface has been improved this past year, responses from users with different technical background is still desirable in order to improve the system.
In this stall I will demonstrate the latest features, which include:
- The support for seven recently added languages: Faroese, Albanian, Asturian, Catalan, Irish Gaelic, Manx, Scottish Gaelic
- The improved user interface: production of helpful tips for users when they specify their goal too narrowly
- The improved user experience: reduction of the time the user has to wait between user interactions.
The purpose of the demo is to gather feedback on the current features and discuss possible future ones.
We present the current implementation of The CLaDA-BG Dictionary Creation System. It is used for creation, examination and editing Bulgarian BTB WordNet. In the demo we will show the main functionalities. The system provides mechanisms for editing all the aspects of a lexical entry, including definition, lemmas, relations, examples, order of lemmas, simultaneous observation of several lexical entries. The system supports access for language resources such as machine readable dictionaries and corpora. The system is implemented as a client-server web-based editor using a thick client model. The system stores in a log file each editing step, the name of the person who edited, and at what time the edit was done. In this way, we can track back states of the data and repair errors if necessary.
EOSC-Related Activities
{kind=link}
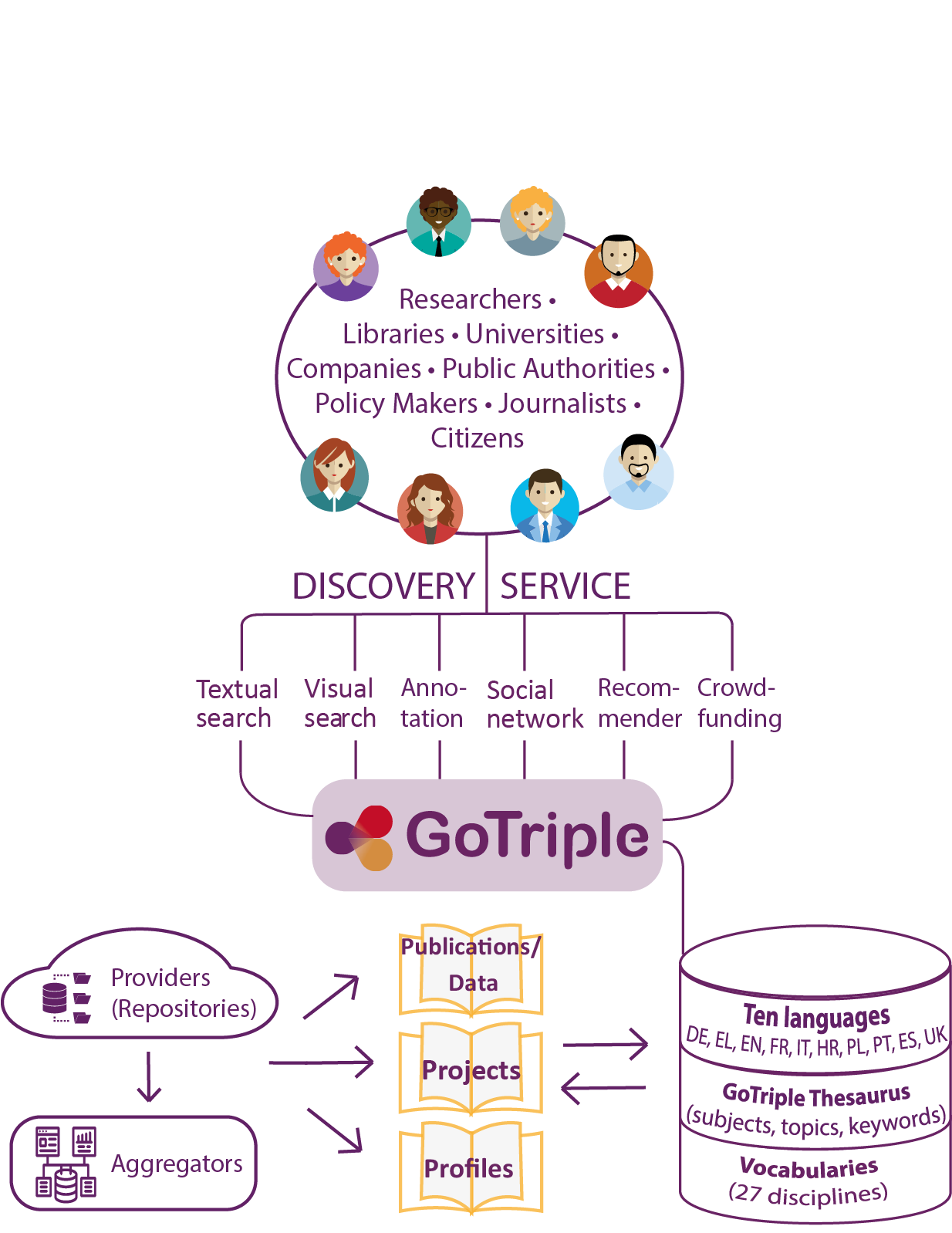
The GoTriple discovery platform is mainly aimed at researchers in the social sciences and humanities by providing access to scientific resources from various European databases, aggregators and also various repositories. Three main types of data are made available to users:
- Publications and datasets
- Researcher profiles
- Research projects.
The platform is developed by the TRIPLE project, funded under the Horizon 2020 European programme, which started in October 2019 and ends in May 2023. Its consortium consists of 21 partners from 15 European countries. We would like to take the opportunity of the CLARIN Conference and Bazaar session to invite you on board and register with the platform, by presenting to what extent GoTriple is innovative and showing its new research and collaborative opportunities.
First, we will present the main architecture composed of the search engine at its centres and the five innovative services that each answer to users' requirements. The set of resources covers 10 languages (Croatian, English, French, German, Greek, Italian, Polish, Portuguese, Spanish and Ukrainian).
In addition to this new openness in terms of multilingualism, the platform was also created to increase the visibility of European researchers beyond their national borders. GoTriple provides access to the work of researchers in their native language, offers services to connect between researchers, and facilitates interdisciplinary collaborative opportunities. Researchers can create their profiles, present their work and connect via a social network that works by cooptation according to their interests.
The GoTriple platform is part of a European context, on the one hand as a discovery service of the European research infrastructure OPERAS (Open Scholarly Communication in the European Research Area for Social Sciences and Humanities), and on the other hand within the EOSC (European Open Science Cloud), by integrating the principles and recommendations of open science such as FAIR data - and because it is proposed on the EOSC portal.
In this perspective of open science, the platform has also developed a crowdfunding service to help researchers in SSH to fund small projects through broad citizen participation. The aim of this service is also to increase the impact of research in SSH and to intrigue the interest of the highest possible number of people.
Another fundamental aspect that has driven the project since its inception is its user-centered approach. Users are involved from the creation of the interface and the design of the platform pages, to the innovative services and functionalities to be developed. Through interviews, surveys and workshops, the development team focused on feedback from potential future users of the platform. Researchers and non-researchers are therefore regularly involved in the project.
CLARIN, together with DARIAH and CESSDA, has built the SSH Open Marketplace, a discovery portal which pools and contextualises resources for Social Sciences and Humanities research communities: tools, services, training materials, datasets, publications and workflows. Its creation has been funded under the SSHOC project, becoming as such a key component of the SSH branch of the European Open Science Cloud (EOSC) and involving partners beyond the initial scope. This discovery portal, initially populated with ~5 000 items, is open for new contributions and enrichment/improvement of the existing records. A lot of CLARIN-related resources have already been shared in this way to increase their discoverability.
How can you get involved? How can the SSH Open Marketplace support CLARIN research communities? What are the technical choices behind the service that are supporting the initial vision to enable discoverability? These are some of the questions that the demo of the SSH Open Marketplace would like to open and discuss with the audience at the CLARIN Bazaar.
We present the contribution of TEXTUA (University of Antwerp) to the ongoing EOSC Future project as Linked Third Party for CLARIN.
In the scope of a test science project on COVID-19 metadata, we develop an ontology of COVID-related topics which optimises cross-referencing across different scientific disciplines. We ensure that this ontology is societally relevant by first applying state-of-the-art topic modelling techniques to parliamentary data and social media data from the COVID era, and then integrating the extracted topics into our ontology. Lastly, we validate to what extent we can automatically label parliamentary data and social media data with this ontology to allow for automated monitoring of the public debate.
The FAIRCORE4EOSC project focuses on the development and realisation of core components for the European Open Science Cloud (EOSC). Supporting a FAIR EOSC and addressing gaps identified in the Strategic Research and Innovation Agenda (SRIA). Leveraging existing technologies and services, the project will develop nine new EOSC-Core components aimed to improve the discoverability and interoperability of an increased amount of research outputs.
The FAIRCORE4EOSC project will deliver nine new EOSC-Core components in support of a FAIR research life cycle, bridging the gaps identified in the EOSC SRIA. More specifically, the components will enable an EOSC PID infrastructure, an EOSC research software infrastructure, support for sharing and access to metadata schemas and crosswalks and offer advanced research-intent driven discovery services over all EOSC repositories.As one of the partners in the project CLARIN is leading the case study dedicated to Social Sciences & Humanities. In this case study CLARIN will integrate its DOG, the CLARIN Virtual Collection Registry and the Language Resource Switchboard with the EOSC MSCR, the EOSC DTR and the EOSC PIDMR in order to (i) make their functions and content available beyond the SSH Cluster borders to all EOSC users, (ii) benefit from the services and content (e.g. data types, crosswalks) available from other communities and infrastructures via the EOSC MSCR and DTR. Moreover, the integration with EOSC registries will make CLARIN domain language data resources available via the EOSC PIDGraph and the EOSC RDGraph. The CLARIN Virtual Collection Registry will indirectly benefit from this integration, relying on common PID frameworks, sharing of crosswalks and schemas.
Overall the discoverability of language data hosted in the CLARIN domain should get improved through use of the proposed EOSC MSCR and Graph components, improving options for reuse of the data and its augmentation with other relevant data from other sources - for instance by inclusion in virtual collections. This effort will also lead to faster and easier processing of language data that is referred to with a persistent identifier.
New Initiatives to Enhance Data and Services Coverage
As of 2021, a group of researchers from different areas (oral history, sociolinguistics and computer science) dedicated to integrating technology in academic research based on interviews (see www.speechandtech.eu) has created a new type of Resource Family for the CLARIN catalogue of scholarly resources: The Oral History Resource Family. This was specifically created for this type of legacy data: interviews that have a history of provenance before they are published on the web. The first collection of this kind is Voices from Ravensbrück. Ravensbrück was a female-only Nazi concentration camp situated near Berlin to which women were deported from all corners of occupied Europe: Poland, the Soviet Union, Germany, Austria, Belgium, The Netherlands, France, Spain Hungary, Yugoslavia and Italy. The female prisoners thus endured their suffering in a multilingual environment.
After they were liberated by Soviet troops on April 30, 1945, the women returned to their own country, or emigrated elsewhere. Decades later, when the survivors started to pass away, the need was felt in several countries to preserve their personal stories by conducting interviews with them. Either via audio or video, filmers, journalists, researchers, culture heritage institutions and small associations collected their stories in the local language, thereby creating public and private archives. With the advent of digital technology and the web these became potentially accessible throughout the world. But how to identify all interviews related to Ravensbrück and bring them together in a coherent structure?
The Voices of Ravensbrück initiative is a first step in this endeavour. Through web research and by creating a network, interviews were identified in Italian, Dutch, German, English, Polish, and Ukrainian. For the first four languages, metadata was collected and entered into a CMDI oral history metadata scheme. For some interviews, transcriptions were created. This multilingual corpus of interviews offers ample possibilities to study this topic from a multidisciplinary perspective, taking into account language, non-textual features, gender, narrative styles, interview styles, archival approaches to interview collections, and many more. To outline the specific narrative character of these types of resources we will present a story-telling cartoon about Voices from Ravensbrück at the Bazaar.
CLARIN’s mission is to create and maintain an infrastructure to support the sharing, use and sustainability of language data and tools for research in the humanities and social sciences. Our focus is on Sign Language (SL) data. As a collaboration project of four CLARIN Knowledge Centres with expertise in SL we have created a Resource Family portal that makes such resources and datasets more visible and accessible for users across the globe.
We have created a CRF page for both SL corpora and SL lexica (which are typically derived from corpora). We worked along the following lines:
- Make an inventory of the material (datasets and resources) offered by K-Centres with expertise in SL
- Make an inventory of other datasets in the VLO which may qualify as members of the new CRF by contacting the right holders
- Make an inventory of any other material (e.g., new datasets, annotation tools, manuals) not yet accessible through the CLARIN Infrastructure by sending out questionnaires to SL communities
- Explore and implement an extra metadata field in current profiles for ‘modality’, so as to refer to SL resources as a visual-gestural modality, stimulating or forcing other providers to specify this for their metadata.
The current CLARIN SL Resource Family comprises 51 corpora and 28 lexicons. Part of these can already be found via their metadata in CLARIN’s Virtual Language Observatory, others cannot but are shared under Creative Common licenses, and for a part the accessibility is still under negotiation. We believe this resource family is an important instrument to highlight SL language resources.
The people and K-centres involved are: Henk van den Heuvel & Onno Crasborn Radboud University, K-Centre ACE; Marie-Anne Sallandre, Université Paris 8 & CNRS SFL, CORLI-K-Centre; Eleni Efthimiou & Stavroula-Evita Fotinea, ILSP/ATHENA RC, K-Centre NLP:EL; Johanna Mesch, Stockholm University, K-Centre CLARIN-SMS.
MATEO (MAchine Translation Evaluation Online) is a CLARIN 'Bridging Gaps' funded project that aims to create an open, accessible platform for machine translation evaluation for both technical users and novices. The MATEO project started in July 2022 and will run for one year.
Machine translation is all around us, and to push its quality forward a variety of automatic metrics exists to compare the quality of machine translations with reference translations. Yet, an accessible, unified approach to use these evaluation metrics is missing. With our proposal, MATEO: MAchine Translation Evaluation Online, we bridge this gap. We prioritise technical and non-technical users by open-sourcing both an advanced Python tool and a user-friendly web interface with ample visualisations and options. The project seeks to support researchers of SSH (Social Sciences and Humanities) and beyond in their MT-related research endeavours. Additionally, it will improve digital literacy of non-expert users by allowing them to easily evaluate machine-generated translations. The interface will be incorporated in the CLARIN B-Centre of INT-NL.
At the CLARIN Annual Conference, we are explicitly looking for your feedback for this alpha version, so if you (want to) make use of machine translation evaluation tools to gauge how feasible machine translation is for your work or to evaluate MT systems, please come visit this demo and let's have a chat! We would love to hear from you: What are your needs and priorities? How can we make your research life easier?
ParlaMint is a CLARIN flagship project, which contributes to the creation of comparable and uniformly annotated multilingual corpora of parliamentary sessions. The data, the developed standards and the results are publicly available. The project has been conducted in two stages: ParlaMint I (July 2020 – May 2021) and ParlaMint II (December 2021 – May 2023).
ParlaMint I created and made available corpora for 17 languages, and started to use them in training and research. ParlaMint II upgrades the XML schema and validation, extends the existing corpora to cover data at least to July 2022, adds corpora for new languages, further enhances the corpora with additional metadata, and improves the usability of the corpora. ParlaMint data has already been successfully used in various observations, experiments and hackathons.
Come to our stall to see our progress with adding more parliaments (now up to 27), making ParlaCLARIN TEI standard richer and more stable, using NLP technology and use-casing contemporary parliamentary data in a multilingual context.
Your feedback is very welcome! If your parliament is not yet part of ParlaMint, we would be happy to share with you how to include it by yourselves with the support of the developed infrastructure!
Digital resources for the Serbian language are in continuous evolution, this project aims to contribute especially to the Serbian-Italian language combination. The idea of the project was to build new web services (ws) on the basis of the existing Jerteh web services: It-Sr-NER-ws would enable monolingual (sr, it,...) and bilingual NER annotation of aligned text, for example it-sr. Test dataset is prepared and shared that includes parts of novels written by Serbian writers translated into Italian and by Italian writers translated into Serbian. The motivation and inspiration were found in a lack of tools and resources that enable annotation, exploration and analysis of bilingual aligned it-sr texts. The team members have produced and explored aligned texts for different language pairs. Among produced sentence aligned texts are a number of the most important classical and modern it-sr novels. On the other hand, NER for Serbian was developed and tested on literary works, and it was recently used to annotate the Serbian ELTeC collection with NER. NER for the multilingual text collection of literary work (ELTeC) has been previously analysed, but it was not applied to aligned (parallel) texts. Aligned texts enriched with NE are a powerful tool for the improvement of teaching and learning both Serbian in Italy and Italian in Serbia. At the same time, the results can be applied to the fields of translation and lexicography for both languages, Italian and Serbian. We will be happy to provide you more information and share our experience at the CLARIN Bazaar in Prague.
DELAD stands for Database Enterprise for Language And speech Disorders, and is also Swedish for SHARED. DELAD is an initiative to share corpora of speech of individuals with communication disorders (CSD) among researchers. We do this in a GDPR-compliant way and at secure repositories in the CLARIN infrastructure. CSD are difficult to find, very costly to collect, and for privacy reasons hard to share. On the other hand, due to their small size and dedicated purpose, they should be combined to be suited for re-use. A strong need is felt by the research community to bring together existing and new CSD in an interoperable and consistent way that is both legal and ethically safeguarded.
Together with CLARIN-ERIC DELAD organises workshops to work on guidelines and solutions regarding legal, ethical and technical issues. In this light, steps are made to get a clear view on use cases to mitigate the risks for participants in the light of the GDPR.
In our contribution we will describe the latest developments at DELAD. We will address our guidelines on consent and data storage, audio/video annotation, and the DPIA role play material we have developed. We will include the latest feedback from our online workshop in September this year.
New Collaborative Links
Lingua Libre is a project developed by Wikimédia France, which aims to build a collaborative, multilingual, audiovisual corpus under free licence in order to: (1) expand knowledge about languages and in languages in an audiovisual way on the web, on Wikimedia projects and outside and (2) support the development of online language communities — particularly those of poorly endowed, minority, regional, oral or signed languages — in order to help communities accessing online information and to ensure the vitality of the languages of these communities.
Lingua Libre is a tool that allows to record a large number of words in a few hours (up to 1,000 words/hour with a clean word list and an experienced user). It automatises the classic procedure for recording and adding audio-visual pronunciation files onto Wikimedia projects. Once the recording is done, the platform automatically uploads clean, well-cut, well-named and apps-friendly audio files, directly to Wikimedia Commons.
The Generations and Gender Programme (GGP) is an interdisciplinary research Infrastructure on population and family dynamics. It collects, processes and disseminates cross-nationally comparable, longitudinal data on young adults, families, and the life courses of women and men. It enables researchers to address urgent scientific and societal challenges concerning the changing lives of individuals and related demographic changes, including low fertility, social inequalities, work-life balance, gender roles, intergenerational support and family diversity. The GGP’s collection currently includes data from around 200,000 people from more than 25 countries. The GGP operates as an open-access infrastructure. As of today, it counts over 4000 registered users worldwide. The main dataset produced by the GGP is the Generations and Gender Survey (GGS). In addition to the GGS, users have access to the contextual database which contains demographic, economic and policy indicators, that may be linked to data from the GGS.
CLARIN Committees
The User Involvement Committee (UIC) is a committee that reports to the Board of Directors. Its main responsibility is to facilitate and promote the CLARIN ERIC User Involvement activities, such as surveys, reports, financing instruments and outreach. Its main tasks include: (1) facilitating the UI initiatives conducted by CLARIN ERIC, (2) promoting the UI financing instruments within their consortium and networks of researchers, (3) promoting UI participation at the relevant national and international UI events, and (4) facilitating the UI surveys conducted by CLARIN ERIC.
The main responsibility of the Standards Committee is to advise the Board of Directors on the adoption of standards to be supported by CLARIN ERIC. Its main tasks include (1)t o collect, consolidate and prepare for publication in a single place its findings and recommendations related to standards; (2) to maintain the set of standards supported by CLARIN and adapt them to new developments within or outside CLARIN; (3) to publish and promote the standards supported by CLARIN; (4) to develop and implement procedures for the discussion of recommendations and the adoption of new standards; (5) to ensure harmonisation of standards between CLARIN ERIC and related initiatives; (6) to ensure communication with international standards bodies such as (but not limited to) ISO; and (7) to advise the Board of Directors in all matters related to standards.