Written by João Silva
LX‑DepParser is a syntactic dependency parser for Portuguese. In syntactic dependency parsing, a word (the head) is connected to one or more words (the dependents) by directed arcs, forming a directed graph. The link between a head and its dependent indicates that the occurrence of the dependent in its specific position in the sentence is made possible by the occurrence of the head. These arcs are typically labelled with the name of the grammatical function (e.g. subject, object, specifier, etc.) that mediates the relation between the head and dependent. The main predicate of the sentence, typically a verb, has no head and is marked by an arc labelled as a root.
LX‑DepParser is based on the MaltParser machine-learning parsing engine, trained on roughly 22,000 sentences from CINTIL-DependencyBank, a corpus also presented in this Tour de CLARIN. Under a ten‑fold cross-validation evaluation scheme, the parser achieves state-of-the-art scores for Portuguese, with 94.42% UAS (the unlabelled attachment score, or the amount of correct dependency arcs, ignoring the label) and 91.23% LAS (the labelled attachment score, or the amount of correct dependency arcs, also taking the label into account).
Similarly to many of the other tools in the PORTULAN CLARIN Workbench, LX‑DepParser can be used in three different ways:
- directly in the browser, which is convenient for processing small snippets of text or for getting a feel for the output given by the tool
- by submitting files to be processed, which is useful for batch annotation of large amounts of data
- and from code, through a web service , which provides the greatest flexibility to users in integrating the tool into their own processing pipeline, but requires some coding knowledge.
When used in the browser, the user can input a small snippet of text and see the parsing result in the same browser window. This output can be shown in a user-friendly format, which provides a graphical representation of the dependency relations, meant for human readability. The other two in‑browser output formats present the output in a machine-readable tabular format that matches the actual output format of the tool. The difference between these two machine-readable formats is in the tag set and grammatical dependency principles that are used: CINTIL follows the tag set and principles defined in Branco et al. (2015), while the universal dependencies option converts the CINTIL dependencies into Universal Dependencies (de Marneffe et al., 2014).
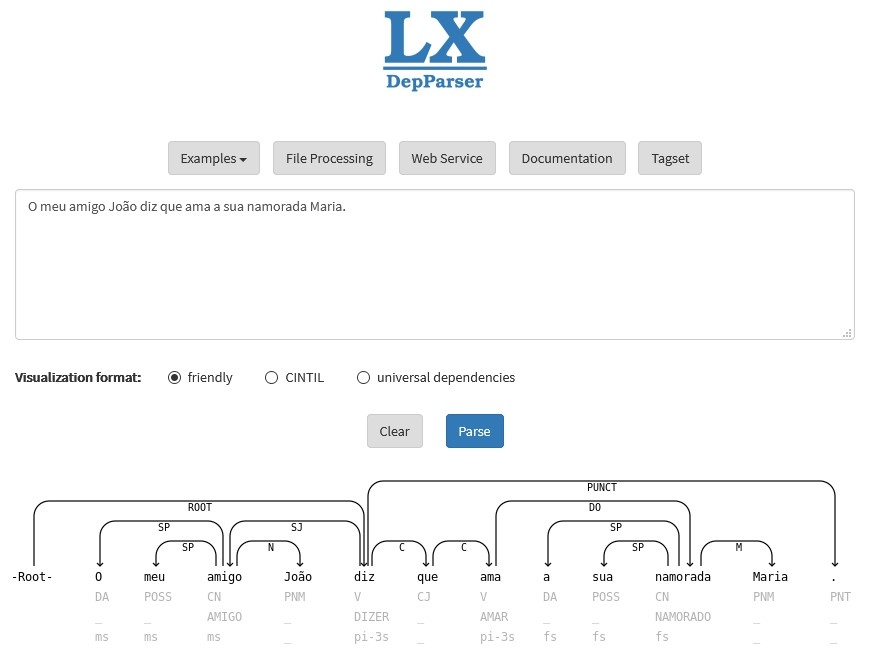
Figure 1 shows the user-friendly output format of the tool for the example sentence O meu amigo João diz que ama a sua namorada Maria ('My friend João says he loves his girlfriend Maria'). The ROOT relation pointing to diz ('says') identifies it as the main predicate of the entire sentence, whereas the SJ (subject) relation pointing to amigo ('friend') defines the latter – or rather the entire phrase that it heads, O meu amigo João ('My friend João') – as the syntactic subject of the main clause.
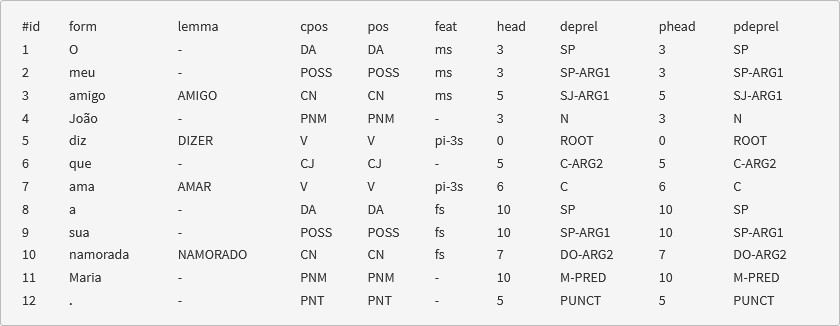
Figure 2 shows the output, for the same sentence, in the CINTIL tabular format. This format is akin to the commonly used CoNLL format and is amenable to being read by a computer. This is also the format produced by the other modes of accessing the tool: the file processing service and the web service.
For natural language processing, LX-DepParser has mostly been used as a component in larger processing pipelines, such as LX‑SRLabeler (for semantic role labelling) or LX‑Suite (a suite of shallow processing tools). It has also been used, for instance, to provide features for a machine-learning classifier in a work where the dependencies produced by the parser were used as features for a classifier that assigns deep lexical types for handling out-of-vocabulary words in a deep processing grammar (Silva, 2014). These grammars make use of lexica with extremely fine-grained syntactic categorisation, but cannot proceed when a word is not found in their lexicon, and relying only on the coarse annotation of a normal part-of-speech tagger leaves too much ambiguity unresolved for a useful and efficient analysis. The classifier was able to use the features provided by the parser to assign fine-grained tags.
For the study of language, the parser has been used to quickly provide a tentatively annotated corpus that was then manually corrected, leading to the creation of CINTIL-DependencyBank PREMIUM. Moreover, from personal communications we are aware that the dependency parser has been used in a classroom setting to show undergraduate students of linguistics its grammatical analyses of input sentences. Note that the parser will sometimes have errors in its analysis, but these possible errors are then integrated into the discussion of the results with the students. If the teacher wishes to show only correct analyses, they can use the manually validated CINTIL-DependencyBank, though in that case they will be restricted to those sentences that are already in the corpus.
References:
Branco, A., J. Silva, A. Querido, and R de Carvalho. 2015. CINTIL-DependencyBank PREMIUM handbook: Design options for the representation of grammatical dependencies. Technical Report DI-FCUL-TR-2015-05, University of Lisbon.
de Marneffe, M.-C., T. Dozat, N. Silveira, K. Haverinen, F. Ginter, J. Nivre, and C. Manning. 2014. Universal Stanford dependencies: A cross-linguistic typology. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC’14), 4585–4592.
Silva, J. 2014. Robust handling of out-of-vocabulary words in deep language processing. PhD thesis, University of Lisbon.