
Please briefly present yourself – your academic career and current position.
I am a Professor of Translation Studies at the School of French, Aristotle University of Thessaloniki, a translator and a literary critic. I have studied Classical, Modern Greek and French literature in Athens (National and Kapodistrian University of Athens) and Paris (Sorbonne-Paris IV), and I was acquainted with corpora and digital tools during my PhD research on translation technologies at Panteion University of Social and Political Sciences. Having an IT background, acquired through informal training, and influenced by the French school of lexicometrical/textometrical analysis, I then took the digital approach to literature. My research focused on corpora and text analysis, text representation and visualisation and their impact on text interpretation, and I adopted the hermeneutical method, according to which text analysis is always qualitative, no matter if the tools and algorithms execute routines to provide quantitative data.
Apart from text analysis, I am very interested in the digital textuality from a communicative, semiotic and literary point of view, and I have published a book on digital literary studies (with Katerina Tiktopoulou). Being a founding member of the Semiotics Laboratory at the Faculty of Philosophy, as well as of the Digital Humanities Lab, where I was the first director, I have integrated digital methods and tools in all my graduate and postgraduate courses on literature, translation and semiotics and created two specific courses on computer-assisted literary translation and literary studies. I am currently working on the translation of Geoffrey Rockwell and Stefan Sinclair’s book on the philosophy and methods of hermeneutical text analysis in the humanities, Hermeneutica, which will be published in Greek soon, and I am preparing an introduction to the digital humanities, aiming to contribute to the consolidation of this emerging field in Greece.
How are you involved with CLARIN:EL and its :EL Knowledge Centre?
I have been collaborating and sharing experiences on the use of language technologies in literature and translation with researchers from ILSP/ATHENA, in particular Maria Gavriilidou and Stelios Piperidis, since the 1990s. So, when they set up the Greek CLARIN network they contacted me, and since 2014 I have been part of the network on behalf of my university. Since CLARIN and DARIAH came together in Greece in the new infrastructure, Apollonis, I have been coordinating Aristotle University’s Clarin-Apollonis team in the network.
We deal mainly with language technology in the humanities and social sciences and focus mostly, but not exclusively, on text (and discourse) analysis. Our goal is twofold: to create and host resources, especially corpora, in the field of the humanities and social sciences, as a base for electronic analysis; and to use these resources in seminars and presentations in order to encourage colleagues and students to join the language technology community, through precise case studies dealing with specific domains. For me, presenting easy-to-use, open-source tools to the community is a deliberate and conscious choice, so that colleagues and students can immediately see the benefits of language technology in their own research. Until now, we have had more than 1,000 registrations for our seminars, and for the new academic year we plan to focus systematically on the more complicated functions of tools such as Voyant Tools and CATMA, or Orange Textable. All information about our seminars and their videos can be found on our website.
I personally use the CLARIN:EL infrastructure to host and analyse my corpora. I also supervise Aristotle University’s repository and coordinate my team’s work and contribution to the infrastructure as well as our training and research activities. I take part in the training, by organising and giving seminars and talks, and develop our collaboration with NLP research communities abroad. Our current training activity is our contribution to the NLP:EL Knowledge Centre, as some of the videos and presentations of our seminars and talks are also available through their interface. Finally, I support the users of Aristotle University’s repository in their questions concerning Language Technology in humanities research. I am happy to say that, as result of our activities, the first community on text analysis has been built and new courses have been introduced in the departments’ curricula, such as the one on quantitative and qualitative text and discourse analysis in the School of Political Sciences at AUTh.
You have contributed to the Greek CLARIN infrastructure with resources of your own. Which resources are these? What are their main features and what is their importance for the research community?
I use the CLARIN:EL infrastructure to host and analyse the monolingual and parallel corpora that I need for my own projects in the fields of Modern Greek, French literature and translation. In relation to literary texts and translations, I would like to stress a permanent problem, which is the restrictions we face due to copyright. Although raw and annotated corpora are ‘bags of words’, which the typical reader can hardly read, we always face licensing restrictions, which prohibit us from sharing available resources with the community, while one of greatest problems of the NLP community in Greece is the scarcity of resources. This is the reason why I always try to strive for open access; for example, the parallel corpus of French literary works translated into Greek (FREL), which I initially created and which can be used both in translation teaching and practice, is accessible through a dedicated interface (below). However, some of my corpora are not in the public domain and can only be accessed upon demand.
Some of the texts contained in FREL, though, are included in the public translation corpus GLTC that is accessible through the CLARIN:EL Central Inventory.
All the corpora that I have created and are hosted publicly on the repository, like the GLTC, are raw literary corpora, which means that initially they are not linguistically annotated; however, they can be processed with CLARIN:EL (as well as external) tools that are integrated with their repository. The corpora can be used individually and in combination with other resources for purposes of linguistic, stylistic, stylometric, thematic, pragmatic and other analyses. We have already used the corpus of the literary works by the writer Alexandros Papadiamantis together with a corpus of his signed translations, and a corpus of his contemporaries (all of which are hosted by CLARIN:EL), in an authorship attribution project, where we tried to identify if some anonymous translations were made by Papadiamantis.
One of my key resources that is not available publicly is the corpus of the literary works of the eminent Greek author Melpo Axioti, whose only novel written in French is hosted in the AUTh repository. This corpus is the result of my collaboration with the text and corpus linguist Dionysis Goutsos, professor at the University of Athens, as part of a wider, collaborative project on exile literature, in which we combined both close and distant reading. This project aims to explore the methods and practices in interdisciplinary ‘big humanities data’.
In such an interdisciplinary approach, researchers need to resort to geomapping in order to effectively visualise the text. To visualise the data in the Axioti corpus I have used Dreamscape, a geomapping service provided by Voyant Tools. Dreamscape is, according to its creators, ‘a preliminary attempt to explore how texts might be represented geo-spatially. The tool tries to identify locations (especially city names) mentioned in texts, and suggests patterns of recurring connections between locations; patterns that might help identify travel of people, ideas, goods, or anything else’. Figure 18 gives an example of geospatial visualisation of Axioti’s novel Το σπίτι μου (‘My home’).
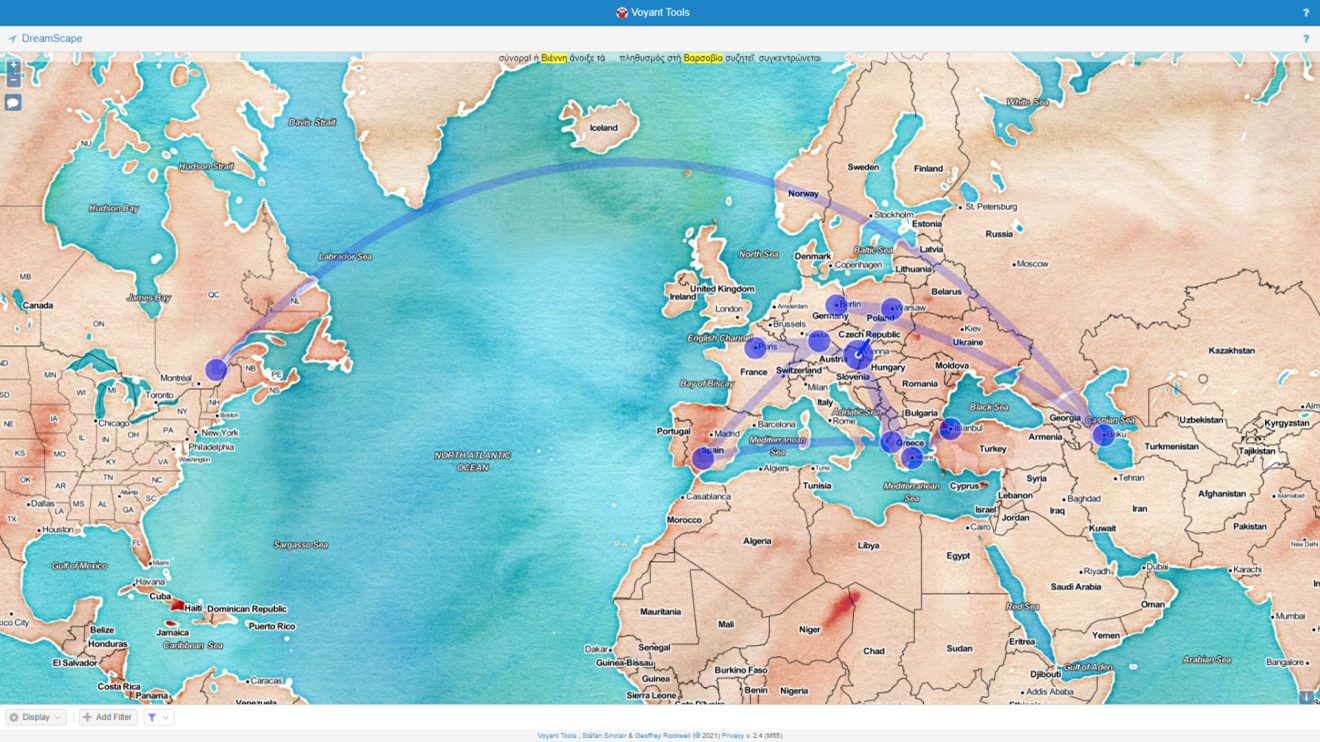
Although Dreamscape is currently in its beta-release stage, which means that the identification of locations is not really fully reliable, it still gives us an idea of how easily such tools could be used in the near future, as well as of their impact on macroanalyses. Of course, accurate geospatial representation of texts is still possible today through a combined use of existing tools – e.g., in the case of Greek texts, I think that CLARIN:EL Annotator of Named Entities can be of great help.
In preparing such resources, has NLP:EL helped you with any kind of linguistic or structural annotation?
Linguistic and structural annotation is very important in literary and translation studies, but what is crucial for qualitative research is to combine them with extrastructural markup. In the Melpo Axioti corpus, we have first used annotation tools provided by CLARIN:EL – specifically, the CLARIN:EL Annotator of Named Entities and the GrNE-Tagger – in order to tag the recurrence of persons and places in Melpo Axioti’s works, and the ILSP Feature-based multi-tiered POS Tagger and ILSP Lemmatizer to study the morphological changes in her language, which are connected with her ideological choices in different periods of her work. Afterwards we used CATMA, which is a tool for the extra-linguistic annotation of culture-specific concepts associated with a particular word in the text. For instance, we have annotated the occurrences of the word house which is the most frequently recurring lexical word in Axioti’s literary works, and constitutes their central thematic element. We have thereby created a double tagset, in which the house is tagged as either a positive or a negative space, with subsets defined by positive (e.g., ‘home’, ‘friendly’) and negative (‘disgust’, ‘loneliness’) connotations of the word, as seen below.
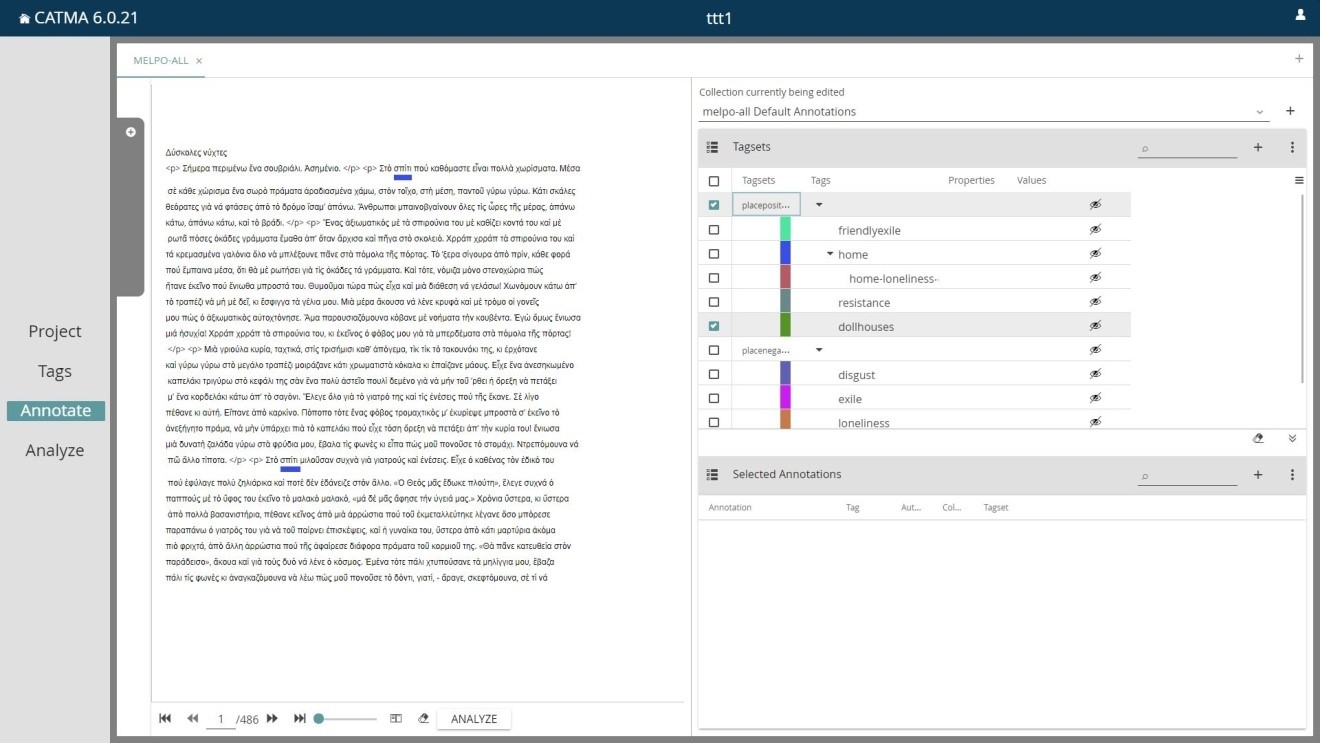
On the basis of this, we then linked the presence or absence of the occurrences and particular meanings and connotations of the term house to broader thematic and stylistic choices, as well as to different periods, in Melpo Axioti’s work. This sort of extra-linguistic annotation is a good example of how a researcher is able to work with qualitative research questions using a digital approach, especially in humanities, as such questions can only be formulated accurately if the user knows the corpus well and tries to shed new light on it by applying both linguistic and extralinguistic tools offered by different developers.
Your research has quite a large and interdisciplinary scope, combining corpus linguistics with approaches like post-structuralist discourse theory, as well as literary studies. Could you present a result or paper in which your research has benefitted from NLP:EL’s involvement? How concretely did your research benefit from NLP:EL?
I was involved in the POPULISMUS project, a research initiative focusing on populism and anti-populism in the Greek press that involved collaboration with colleagues working in political science. This led to several Greek and English publications. My contribution in this project was mostly methodological: after a workshop on text analysis for political scientists in 2014, a team was created that I trained in corpus-based analysis. They got acquainted with the digital approach and applied quantitative and qualitative methods to confirm their theoretical hypotheses on populism, based on the so-called Essex School analysis. This project proves that hermeneutical text analysis as a method can apply to all kind of texts and research, on the condition that the specialists formulate and then test clear and solid hypotheses. This team is now exploring new paths in quantitative and qualitative analysis, integrating different methods of analysis and AI. A CLARIN:EL seminar, focusing especially on political discourse, was held recently at AUTh, with more than 250 participants from all over Greece, and together with NLP:EL we are now organising a follow-up that will focus on the practical results of the project.
Concerning my work on translation and literature, I would like to present two examples in which my research has benefited a lot from electronic text analysis and annotation. The first one relates to the translation of poetry and prose of Greek authors, like Andreas Embirikos and the aforementioned Melpo Axioti, who wrote in French (three poems by the surrealist poet Andreas Embirikos and some recently discovered short stories written in French by Melpo Axioti, to be published soon). When translating an author’s discourse in a language other than their mother tongue, you face a major dilemma: you need to decide if you are going to translate simply what you read or try to reproduce the author’s style in the original (in this case, Greek). I opted for the second strategy, so I needed to have the most accurate idea of what the author’s style corresponds to and which devices it consists of. In my effort to define it, both textometrical analysis and thematic, morphological and syntactic annotations were of great help to me, in particular the ILSP Feature-based multi-tiered POS Tagger and ILSP Lemmatizer, which gave me an idea of the general use of the author’s vocabulary and their morphological choices, and the ILSP Dependency parser for the prose, which was of great help in studying Axioti’s syntax and identify recurrent patterns representative of her particular style. For example, when exploring synonymy I chose words actually used in the works, focusing on their morphological particularity, and I also reproduced, in the case of Axioti, her particular syntax. Since then, I have relied on similar approaches for all my translations, using linguistic-analysis tools like the aforementioned ILSP POS Tagger and Dependency parser together with Voyant tools and CATMA, with which I try to obtain concrete stylistic evidence as a basis for translating the text. Such a method of combining tools can be of great help not only for researchers, but also for professional translators.
The second example concerns Modern Greek poetry, in particular the work of the poet Kostas Papageorgiou. While studying his work for an essay on his poetry, I had the feeling that the frequency of comparisons in his poetry collections is linked to how his poetic vision had evolved through time. To confirm my hypothesis, I digitalised his collections, loaded them into Voyant Tools (which is accessed also through the CLARIN:EL repository), defined the words introducing comparisons and studied them in term of concordance. The quantitative data confirmed my hypothesis, as it turned out that comparisons occur less and less in his three last collections, becoming replaced by metaphors, where poetic discourse is represented in terms of somatic (i.e., bodily) functions. My study revealed another important role that comparison plays in his work – that is, the different status and function that this trope progressively acquires: at first, it is used to establish an analogy between realities of different nature, while over time it starts to signal the analogy itself, since the second element of the analogy is no longer spelled out and the word that signals the comparison (such as like in English similes) gets suspended. My findings on the frequency, function and transformation of comparison were the basis for an article I published on the poetry of Papageorgiou.
What makes NLP:EL especially invaluable in facilitating corpus linguistic research in the aforementioned fields?
It is researchers who hold the most important position in digital research, and particularly in text analysis. Their deep knowledge of the field and its theoretical framework is a prerequisite, as even the choice of the texts and the compilation of the corpus is crucial for the validity of the hermeneutical analysis. So, there is no digital analysis in vacuum; rather, it starts with a question formulated more or less clearly by a specialist, on the basis of the relevant theoretical premises. Digital analysis permits the confirmation or refutation of these premises, with authentic, quantitative data, which in the hermeneutic cycle of the texts have qualitative value. NLP:EL is really invaluable as it trains researchers how to effectively collaborate and share their methods and resources, thereby enhancing interdisciplinarity in many different ways. It also provides opportunities for exchanges and consultation and generally works as an invaluable forum and a training hub for the Greek NLP community.