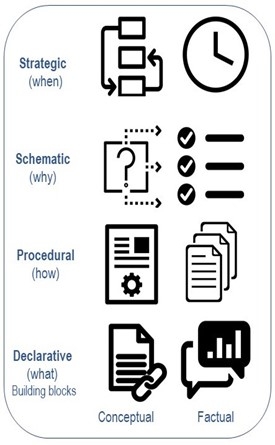
For most institutions, sharing knowledge means sharing declarative information: sharing data, metadata, tools (the “building blocks” of knowledge) and giving access to repository centres with such resources. However, accessing knowledge is not only about “knowing-what” can be collected, accessed or analyzed within a dataset but also refers to “knowing-how” a specific dataset is built, how it can be processed, for which purposes should it be created, used/re-used (“knowing-why”), and following which steps/procedures (“knowing-when”). The French Knowledge Centre CORLI for Corpora, Languages and Interaction (henceforth CORLI K-Centre) is such an attempt: a certified CLARIN K-centre established in July 2020 that has identified through consensus the main steps that need to be carried out in a research involving language corpora along with the main principles that should characterize such investigations. The CLARIN K-centre thus provides knowledge that researchers need in their everyday practice in the following four domains (Figure 1) covering both the factual aspects of necessary content elements (data, metadata, tools, repositories) and the conceptual parts of knowledge (typology of the data, principles of data collection/processing/storage/reuse, usage-based research methods, training, workflows, etc.).
Declarative knowledge: involves information about the most important data and metadata repositories; access to technical manuals and tools; external links to other relevant specialized institutions (e.g., B-, C-, and K-centres), etc.
Procedural knowledge: is about offering advice about proper citation of existing datasets; best practice recommendations for data collection; solutions and training for data processing, storage and research management; advice about transcription and annotation principles, data anonymization, metadata standardization, file conversion, etc.
Schematic knowledge: refers to providing examples of workflows; research questions and options of investigation/adequate types of corpora; guidelines on the establishment of sound research plans; help with the preparation of ethical approval applications; best practice recommendations for making resources Findable, Accessible, Interoperable, Reusable (FAIR), etc.
Strategic knowledge: is about providing information on the necessary steps of a research protocol; access to management checklists, recommendations about data collection unfolding; flow diagrams on data lifecycle, etc.
The CORLI K-Centre is part of the CORLI consortium, a national consortium of more than twenty Universities and research labs involving more than two hundred researchers around France, and dedicated to consensus-based recommendations and digital solutions in corpus linguistics. The Centre is coordinated by the French digital humanities infrastructure Huma-Num and functions as an interactive online platform (accessible here: https://corli.huma-num.fr/en/kcentre) which centralizes and provides cross-border access to knowledge through both proactive and reactive services.
More specifically, with respect to proactive knowledge, the CORLI K-Centre offers best practice recommendations for:
- building corpora and format conversions, accessing existing written and oral corpora repositories;
- metadata standardization procedures, data storage, assessment and re-use principles;
- legal and ethical issues related to corpus management and use, among others.
Users with more specific needs in linguistic analysis have also the possibility to access repositories with more specialized information, e.g. manuals for corpus annotation, practical guidelines for the use of corpus annotation and analysis tools, etc.
Some of the most popular actions of the CORLI K-Centre include: the training opportunities offered every year on the use of digital tools, and regular financial support calls for the finalization and transformation of existing corpora to ensure compliance with the FAIR principles. The development of a FAQ (Frequently-asked questions) page addressing common concerns in these topics as they occur in the questions formulated by the users, further contributes to information access. The users of the CORLI K-Centre platform have the possibility to access most knowledge through the website of the centre, and alternatively through the FAQ, where other landing pages offer the possibility to redirect to related content (e.g., to , CLARIN, other B-, C- and K-centres etc.) and thus continue the journey ideally without the need for outside assistance.
In cases of requests for further assistance, the CORLI K-Centre offers an additional reactive knowledge-sharing service established thanks to a pool of researchers and data specialists who provide further information whenever needed. The way the users interact with the webpage and the provided knowledge is of vital importance to the CORLI K-Centre as these feeds help update the pages and information offered. For this reason, a contact form has been integrated to the platform (easily accessible in a separate page: Contact) offering the possibility to the users who cannot find an adequate answer to their questions to contact the centre directly (Figure 2 for an overview of the website).

In addition to this service-oriented line of work, the CORLI K-Centre is also a research centre that promotes empirical approaches to language, organized in six working groups:
- The Interoperability, queries and corpus exploration team is focused on theoretical and methodological questions related to corpus exploration and annotation practices, interoperability and metadata standardization.
- The Multimodality and new forms of communication team is focused on multimodal ways of communication (gestures, posture, gaze, sign language, etc.) and online behavioral techniques of data collection (eye movements, 3D motion capture, EEG etc.)
- The Multilingualism team works on bilingual and multilingual corpora with special focus on written and oral corpora, language mixing in endangered languages and languages in contact, language acquisition and code-switching, as well as on parallel corpus-based investigations.
- The Legal issues and Data protection team works on the challenges researchers face in their everyday practice with data management, storage and anonymization (GDPR regulations, open science constraints, sensitive data management, international legal practices, etc.).
- The Corpus annotation team focuses on best practices for the management of corpus annotation projects (project conception, establishment of multi-layer annotation manuals, inter-annotator agreement principles, development/use of annotation tools etc.)
- The Corpus assessment team works on the evaluation of language resources (data and tools) and the establishment of homogeneous criteria for resource storing, archiving, sharing and resource quality assessment according to the FAIR principles.
The expertise gathered by the pool of specialists involved in the above groups has led to a great number of outcomes, useful to linguists (all levels of academic expertise) but also to anyone working with corpora or interested in language use, databases, digital tools for data collection, resource exploration and data management (engineers, data scientists, educators, etc.).
With expertise in corpus linguistics, multilingualism and multimodality, the CORLI K-Centre aims:
- to enhance multi-level knowledge and practice sharing following the FAIR and Open Science principles among researchers and other actors interested in language and corpus linguistics,
- to become a major platform of communication and a training portal for younger researchers,
- to facilitate exchange of ideas and collaborations, and support international synergies.