Written by João Silva
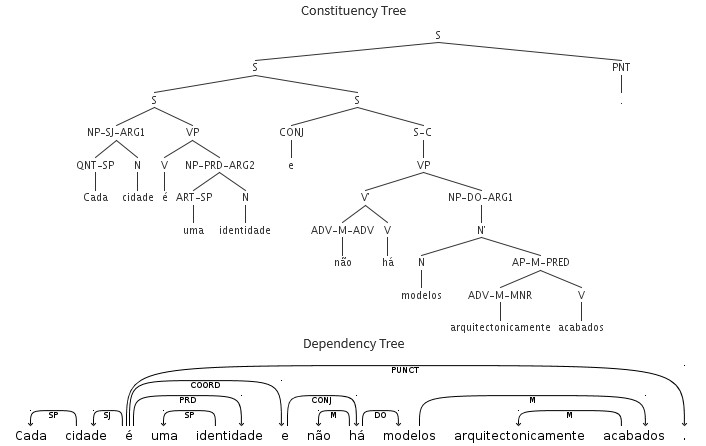
CINTIL‑DependencyBank is a corpus of Portuguese utterances annotated with the representation of grammatical dependency relations, a kind of linguistic information that, roughly speaking, captures the fact that for a sentence to be grammatical the occurrence and position of words depends on, and is constrained by, the occurrence and position of other words in the sentence. The annotation is represented in a machine-readable tabular format.
Such annotated corpora are important resources for the study of natural languages and for the development of natural language processing tools. In the former, they support, for instance, concordancing and the search for syntactic patterns in corpora, which are necessary to check whether theory fits with observed data; while in the latter, they are used, for instance, as training and evaluation data in the development of machine learning parsers (such as LX‑DepParser, also presented in this Tour de CLARIN).
The developmental process of CINTIL-DependencyBank is worth noting, as it sets it apart from other dependency corpora. Generally, the manual annotation of corpora is a very time-consuming process that requires expert knowledge and, for large corpora, it is easy for errors and inconsistencies to occur. Because of this and because of a general lack of expert annotators, many corpora are automatically annotated and then manually corrected. While this can help, inconsistencies can still easily occur and the amount of effort required for correcting the annotation depends on the quality of the annotation tool.

References:
Oepen, S. 2001. [incr tsdb()]—competence and performance laboratory. User manual. Technical report. Saarland University: Saarbrücken.
Pollard, C., and I. Sag, 1994. Head-driven phrase structure grammar. Chicago University Press and CSLI Publications: Stanford.
Silva, J., and A. Branco. 2012. Deep, consistent and also useful: extracting vistas from deep corpora for shallower tasks. In Proceedings of the Workshop on Advanced Treebanking at the 8th International Conference on Language Resources and Evaluation (LREC'12), 45–52.