Written by Maria Gavriilidou and Iro Tsiouli
NLP:EL is the CLARIN Knowledge Centre for Language Technology and Language Resources in Greece. :EL is a relatively new CLARIN K-centre. It was established in March 2020 and is hosted by the Institute for Language and Speech Processing (ILSP) of the Athena Research Centre.
ILSP is a research and development organisation in the area of Language Technology in Greece, whose activities cover a broad range of the Language Technologies spectrum. Besides research and development, ILSP is actively involved in educational activities in collaboration with universities. To complement and support its research efforts in these areas, ILSP continuously invests in developing its Language Resources Infrastructures, prominent among which is CLARIN:EL, the national research
infrastructure on Language Resources and Technologies, which aims to be the central point for Language Technology and Language Resources in Greece.
NLP:EL, the Knowledge Infrastructure for Language Technology in Greece, constitutes an integral part of CLARIN:EL, together with the central catalogue which aggregates resources (datasets, lexical resources, tools, services, and workflows) developed mainly by the national network members, but also significant external resources; it currently hosts 520 resources and more that 40 tools/services.
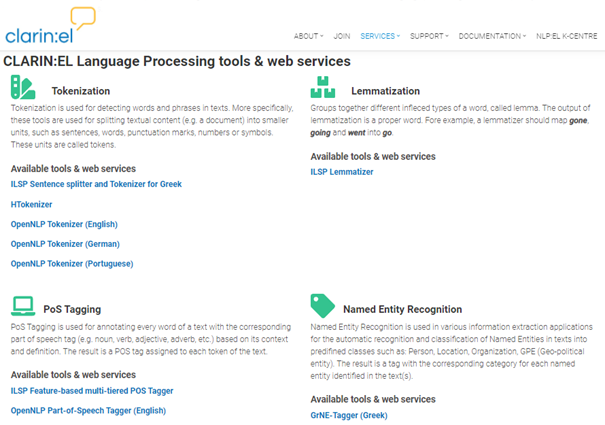
NLP:EL has the mission to support language technology research for the Greek language, the digital readiness of Greek, and sign language technologies research and development. Through its web pages NLP:EL provides a plethora of services, including information about language processing tools and web services. Some of the most frequently used NLP processes have been selected among those offered by CLARIN:EL, that is, tokenisation, lemmatisation, part-of-speech tagging, named entity recognition and chunking. For these, NLP:EL provides a brief definition of each process describing their function and examples to clarify the task they perform; then, a list of the respective tools/services offered by CLARIN:EL is provided and, finally, via a link to the landing page of each tool the users are redirected to the CLARIN:EL repository, where they can view the metadata description of each tool/service and get access to use it. Thus, a user who wants to know for instance what lemmatisation is and why it is useful is guided through the definition and the list of tools that perform this task, from where, based on the metadata descriptions and the usage conditions, they can select the most appropriate one.
NLP:EL also provides videos and tutorials about selected services and applications provided by CLARIN:EL, whether developed by CLARIN:EL members and integrated as web services or developed by third parties. An example of this is a video describing the Named Entity Recognizer (NER) service of ILSP that is available through YouTube. ILSP NER is a tool for the recognition of proper nouns in a text (person names, place names, companies, names of months, days), but also of paralinguistic items like dates, numbers, emails, etc. In addition to the identification of these items, the NER tool annotates them with the appropriate tags (e.g., PERSON, LOCATION, DATE, etc.). The tool is available from CLARIN:EL as a web service. The video, using the NER web service as an exemplifying case, describes the whole procedure a user has to follow when using the CLARIN:EL infrastructure, from the selection of the service from the CLARIN:EL inventory to the uploading of the data to be processed, then to the online running of the service and finally to the downloading of the results and their subsequent inspection and analysis.
As an additional example, there is a webinar recording which presents Voyant Tools, a web-based analysis environment for digital texts (Sinclair & Rockwell) listed in the CLARIN:EL inventory. The webinar was part of a series of training activities whose aim was to introduce various text analysis tools to interested students, educators, language professionals, etc. This webinar was presented by Professor Dimitroulia (see the interview), and the recording was made available publicly.
There are several manuals and guides for tools and/or applications that have been developed by the CLARIN:EL team or that can be accessed through the CLARIN:EL Research Infrastructure. For example, CLARIN:EL hosts an instance of WebAnno, a web service application for collaborative text annotation developed by the Computer Science Department of Technische Universität Darmstadt. Through this platform, users can upload their texts, create their own projects, define their tagsets or use already built-in tagsets, invite other users to their projects in order to annotate texts in collaboration and at the end export the annotation results locally. Naturally, WebAnno has its own documentation; however, documentation manuals have been written in Greek from scratch for CLARIN:EL users, covering all WebAnno user roles (curator, annotator, project manager).
NLP:EL also offers access to services and products in the fields of dynamic sign language synthesis, such as the Fingerspelling keyboard, a virtual keyboard for alphanumeric symbols corresponding to the signs for the 24 letters of the Greek alphabet, and the Dynamic Synthetic Signing environment, which allows users to produce new sentences in Greek Sign Language by selecting the components of each phrase to be produced from a glossary of signs; the users can preview every phrase he or she produces through a virtual signing avatar and modify it if necessary.
Educational materials offered by NLP:EL include scientific publications and slides of presentations in the relevant fields published by the CLARIN:EL network team as well as a list of university courses in the fields of Language Technology, Data Science, Information Technology and Digital Humanities offered by Greek Universities.
There is also a dedicated helpdesk, which supports the users in their quest for information on the above subjects. Personal advice is often sought by individual users on concrete issues that concern them, and these requests are supported accordingly.
Lastly, NLP:EL organises training events, through which knowledge on the domains of expertise is transferred. The training events take the form of webinars, tutorials, hands-on sessions or focus groups, depending on the needs and the audience. Thus, separate events have been organised, dedicated to user groups with different backgrounds (literature studies, social and political sciences, computer science) catering for their special needs; for example, metadata curation and data deposition, use of language processing tools, dockerisation of services and integration thereof into the CLARIN:EL repository, etc.
As a prominent example, NLP:EL organised the CLARIN:EL Summer School 2021, which was held online between 6 and 8 July 2021. It was attended by 75 participants, with backgrounds in Library Science, Language Studies, Education, History and Archaeology, Literature, Computer Science, Digital Humanities and Political and Social Sciences. The participants had the opportunity to get acquainted with the basic concepts of Language Technology and Language Resources, to take a deep dive into data collection, curation and processing, to discover LT-based applications, to hear about the role of national and EU Language Resources and Technologies Infrastructures, and to familiarise themselves through hands-on workshops with the CLARIN:EL Infrastructure, the curation of resources and the use of NLP tools.
With more than 16,400 users and 28,400 page views since the establishment of NLP:EL in March 2020 (based on Google Analytics), the K-centre and the CLARIN:EL inventory, as integral parts of the national research infrastructure, are committed to ensure the digital preservation and readiness of the Greek language, by supporting research in the field of NLP and the development of language technologies in Greece.